

Visionati 是一个包含九个图像到文本 AI 的工具包,可以处理图像字幕、标记和内容过滤。
Visionati 入门非常简单! 只是 上传您的图片或将 URL 粘贴到应用程序中 人工智能将对其进行分析以获得完整的描述。
你可以 选择字幕的角色——例如产品描述的“电子商务”或使用人工智能生成类似图像的“提示”。
一旦你把你的标题摆好,你就可以 向 AI 询问有关图像的任何信息 了解更多背景信息。
借助人工智能图像分析,在几秒钟内为任何内容添加字幕。
Visionati的AI分析还可以 识别图像的关键元素以创建标签 为了更好的资产组织。
因为这项技术经过训练 关注物体、环境和地标,您将提高整体搜索能力。
跨平台利用这些智能标签,从组织 Lightroom 照片到使用 macOS 标签系统对图像进行排序。
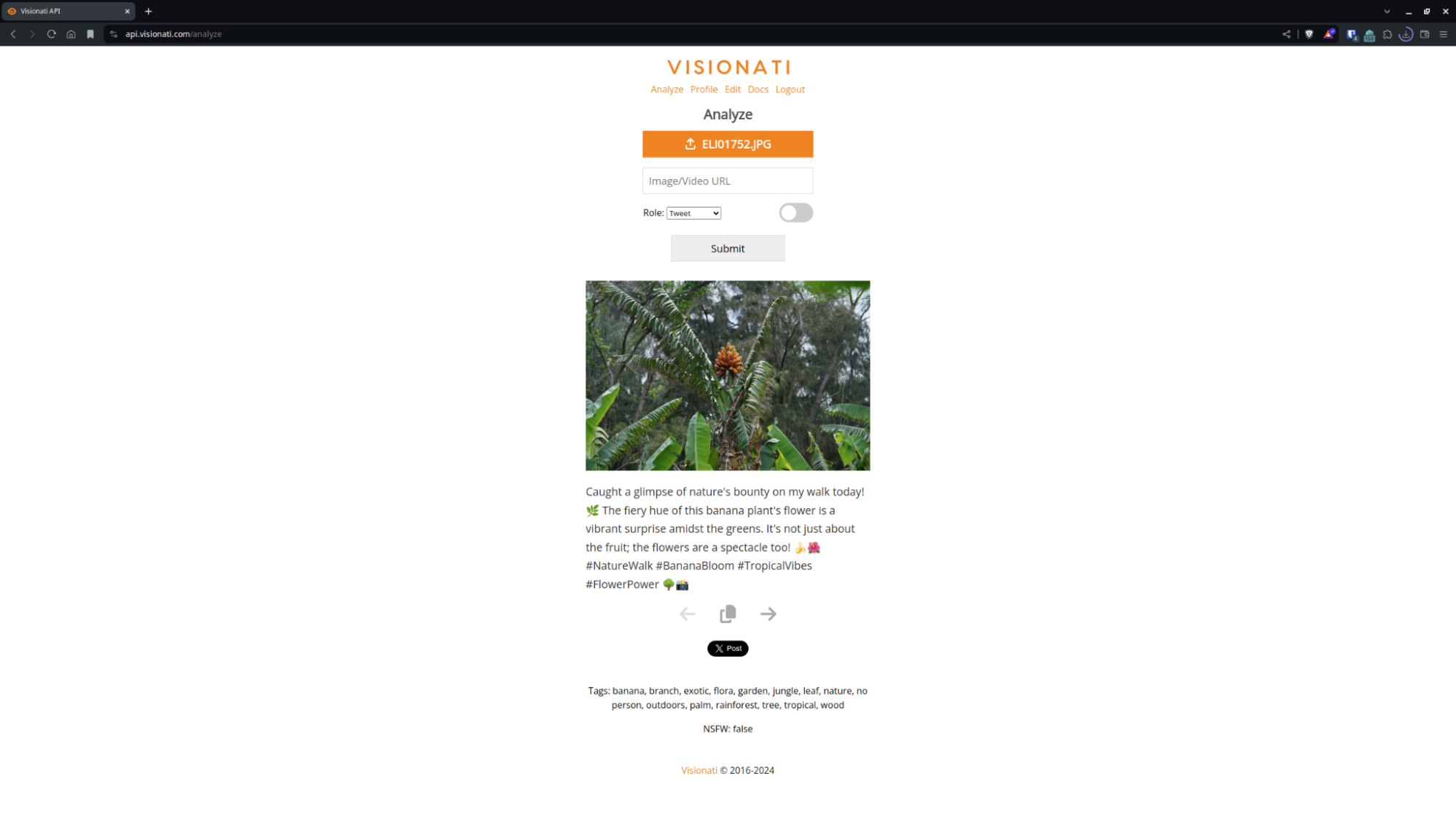
获取对象、环境和地标的描述性标签,使您的图像可搜索。
更好的是,这个工具包可以帮助您 自动检测攻击性图像内容 比如裸体和暴力。
这对于 管理社区和应用程序中用户生成的内容 维护安全的在线空间。
设定您自己的过滤标准 可以按照您的意愿宽松或严格,并让 Visionati 在攻击性图像到达用户之前捕获它们。
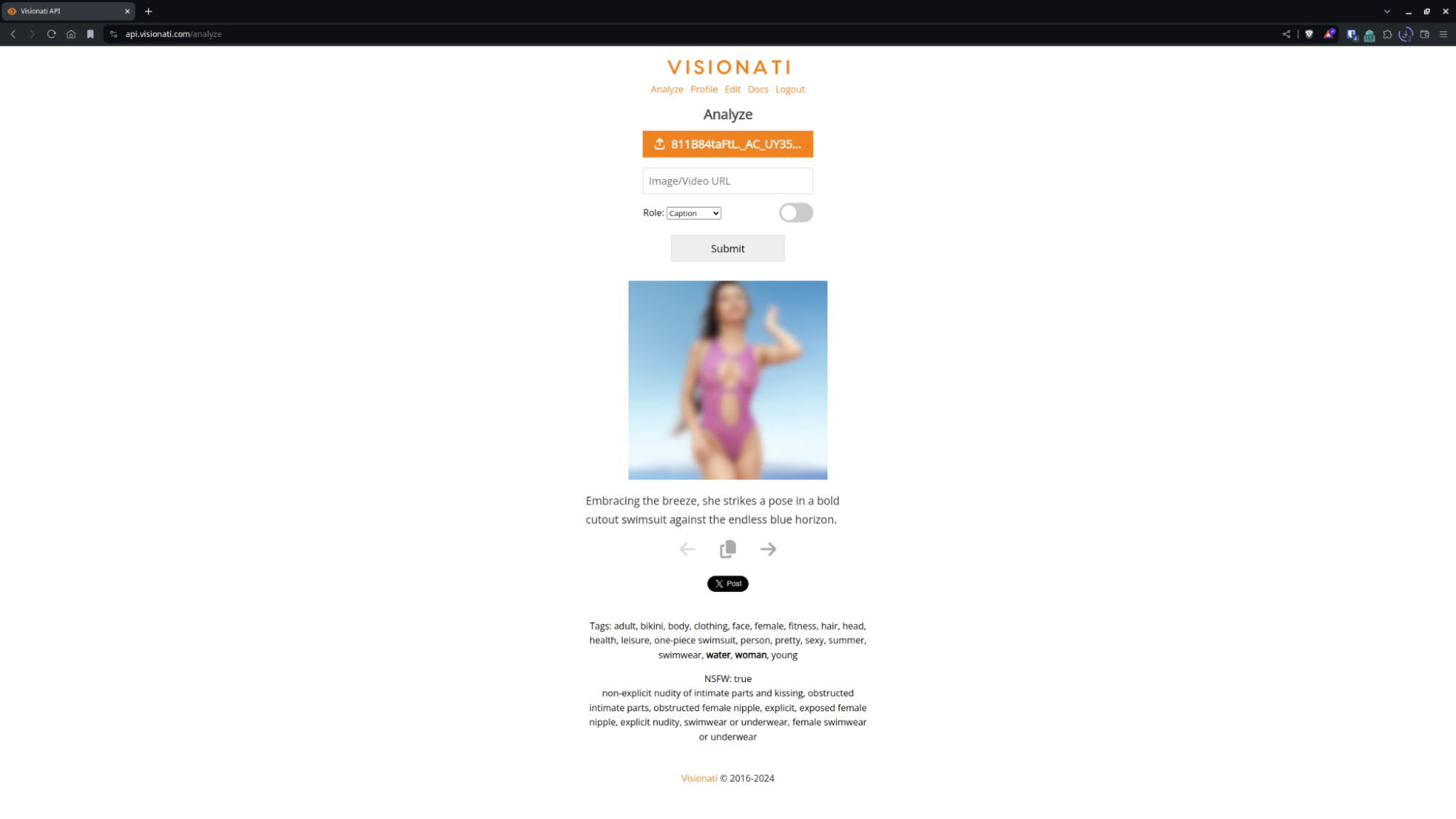
在攻击性图像到达您的应用程序或社区之前检测到它们。
最重要的是,Visionati 是 连接到九种不同的人工智能服务 包括 ChatGPT、Google Gemini 和 Amazon Rekognition。
这意味着你可以 循环浏览多个服务的图像到文本结果 选择产生最佳结果的模型。
由于它们都可以通过这个工具包获得,因此您无需花费大量资金购买不同的每月订阅即可完成此操作。
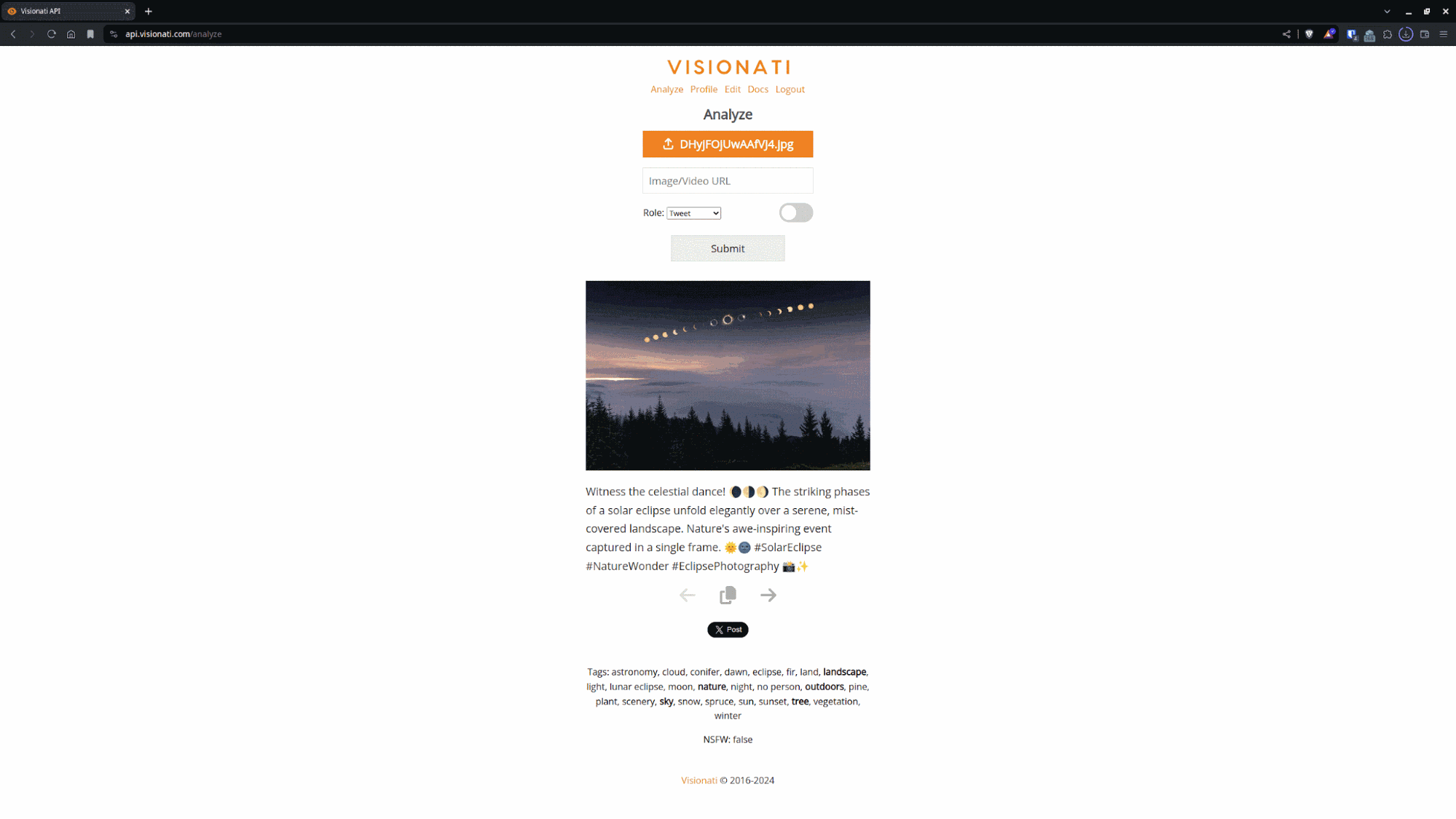
从九种主要的 AI 图像到文本模型获取结果并选择您最喜欢的输出。
Visionati 可以分析、添加标题、标记和过滤您的图像,以便您能够将图像转换为内容策略金矿。
使用 AI 为任何内容添加字幕。
立即获得 Visionati 的终身访问权!